Tecnologia para filtrar comentários online deixa-se enganar pelo amor
Uma equipa da Universidade de Aalto, na Finlândia, confundiu os filtros automáticos criados para detectar discurso tóxico na Internet.

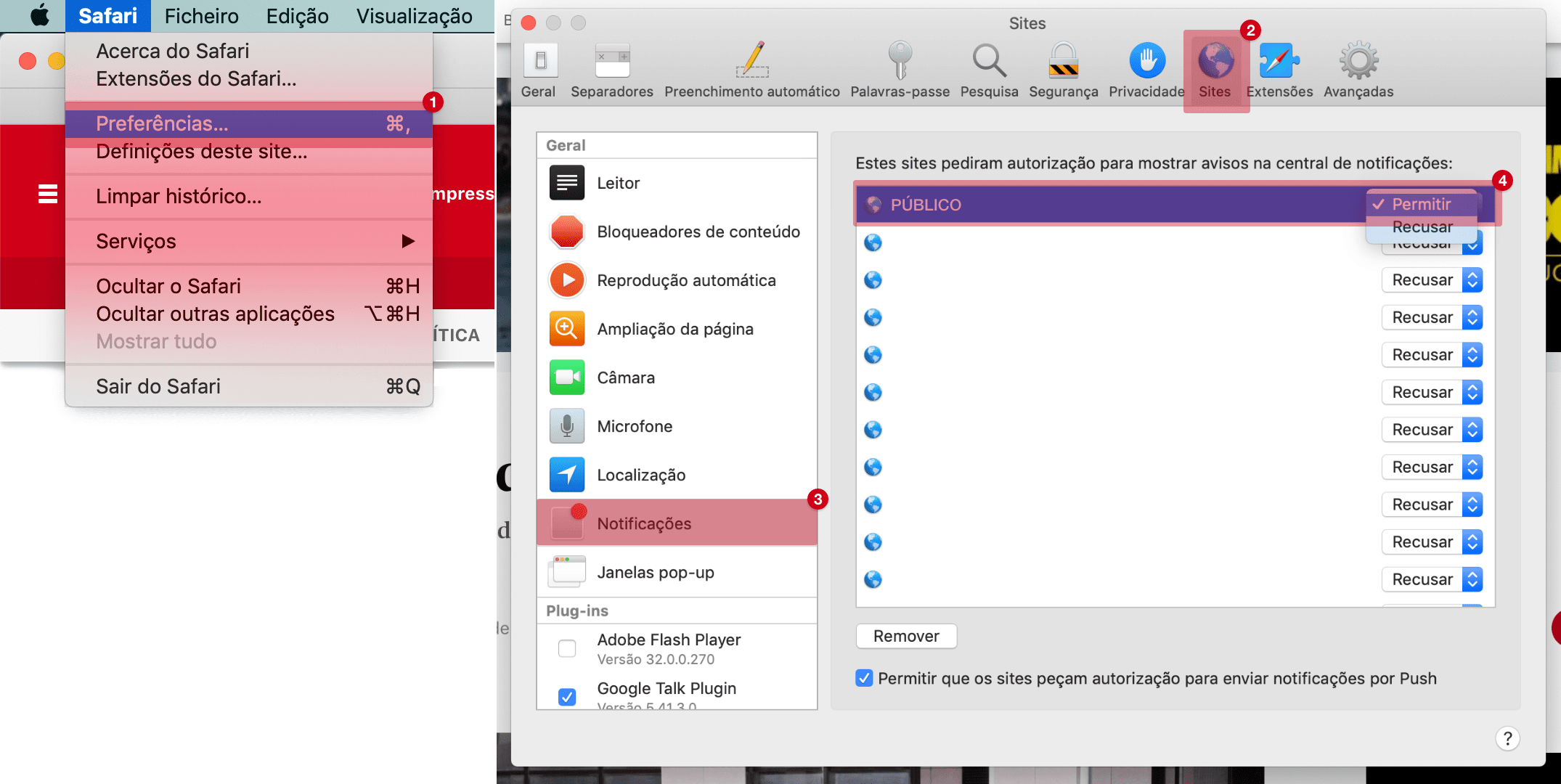
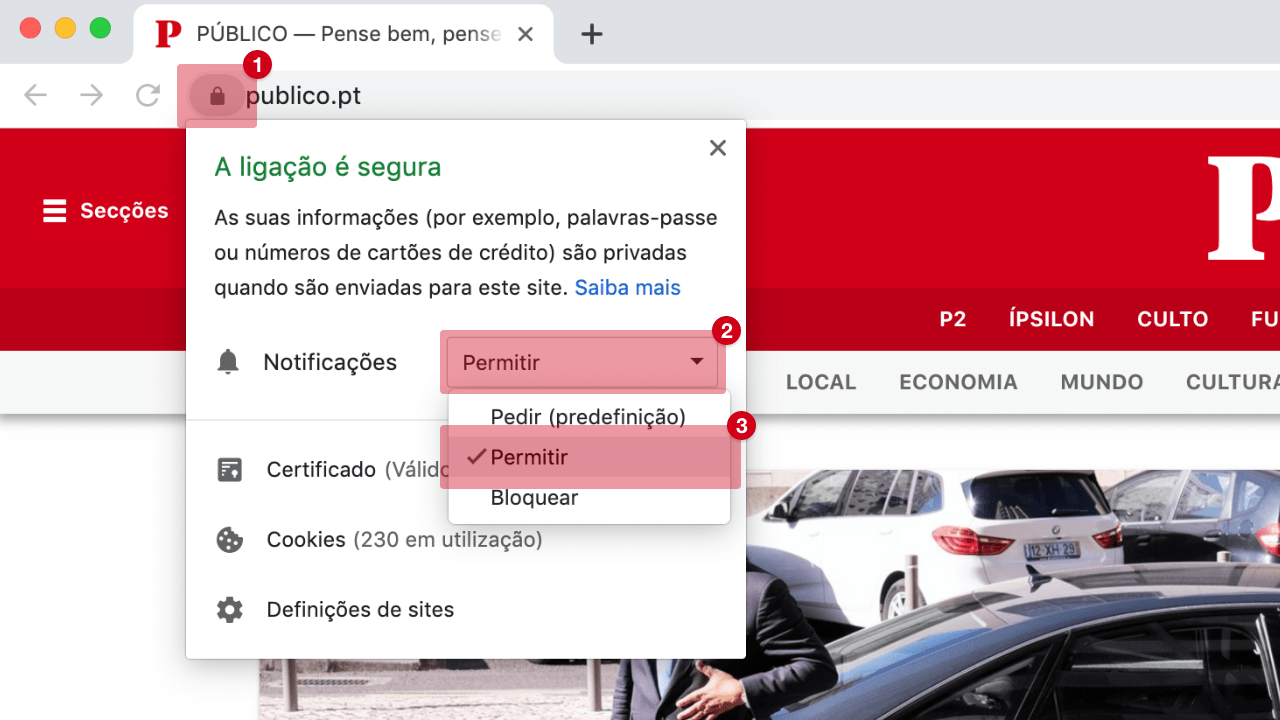
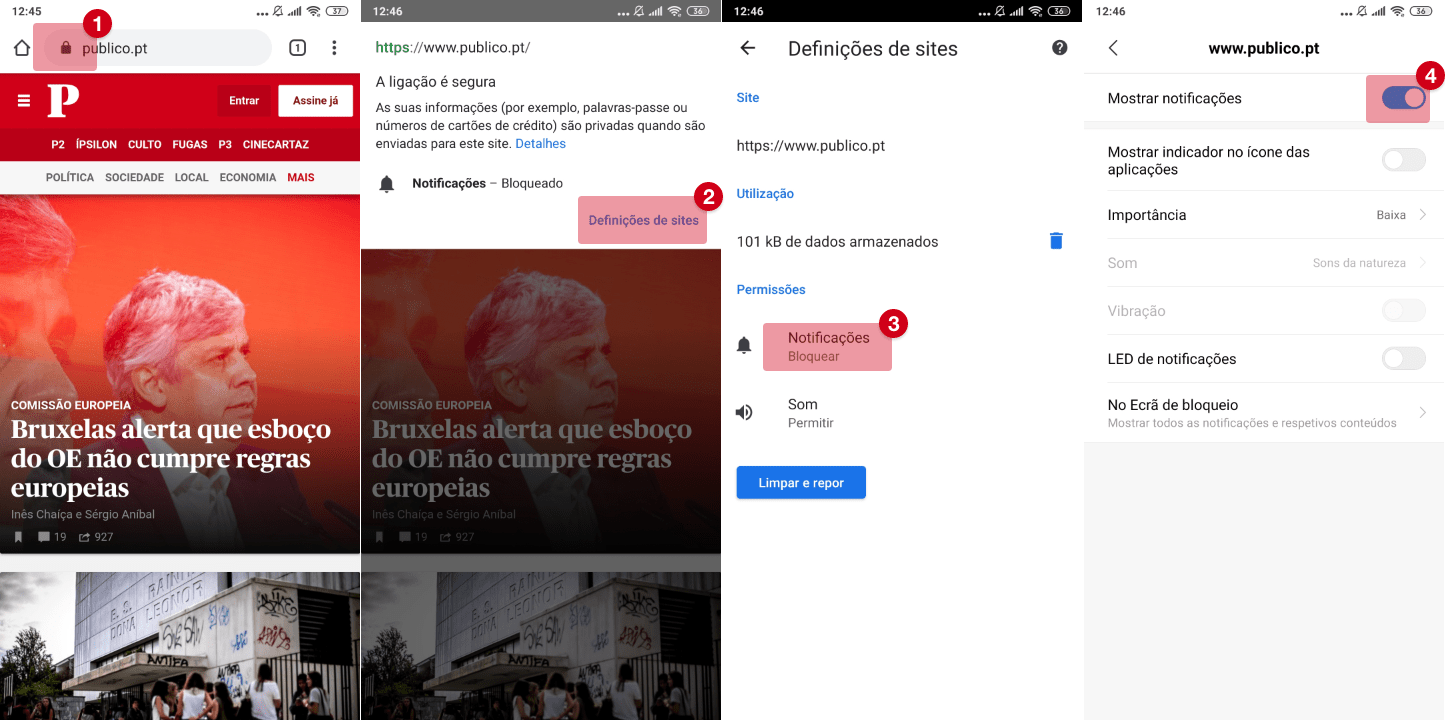
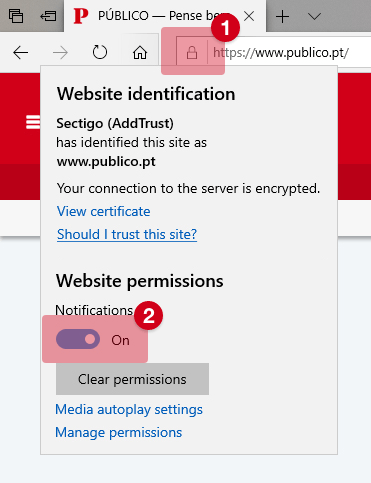
As grandes tecnológicas estão a apostar cada vez mais em sistemas de filtragem sofisticados para detectar e eliminar comentários de ódio na Internet, mas um estudo recente na Finlândia mostra que ainda são facilmente enganados. O sistema do Google, o Perspective, é particularmente sensível ao “amor”.
Grande parte dos sistemas modernos de processamento de linguagem, usados para ensinar as máquinas a linguagem dos humanos, baseia-se na aprendizagem de extensas bases de dados. São usadas para ensinar as máquinas classificar palavras ou frases independentes e analisar textos. Quando se deparam com dados diferentes dos que aprenderam, os sistemas confundem-se.
“Inserimos erros ortográficos, eliminámos espaços e adicionámos palavras neutrais a frases com discurso de ódio”, explica em comunicado Tommi Gröndahl, um estudante de doutoramento da Universidade de Aalto, na Finlândia, que participou na investigação. Foram usados sete sistemas de detecção de linguagem imprópria (dois que analisavam cada letra, número ou pontuação, e cinco que analisavam cada palavra), bem como o sistema do Google. Os oito falharam.
Os resultados foram partilhados este mês no ArXiv, um repositório de artigos científicos gratuitos que ainda não passaram pelo processo de revisão por outros investigadores (peer review).
Em 2017, um grupo de investigadores da Universidade de Washington já tinha mostrado que o Perspective não conseguia interpretar palavras com erros ortográficos. Desde então, o sistema tornou-se mais resistente a falhas de ortografia, mas a equipa finlandesa mostrou que o sistema ainda tem problemas com palavras com conotação positiva – em particular, a palavra “amor”.
Para tal, o ponto de partida foram bases de dados de comentários racistas, sexistas, e normais feitos na Wikipédia e no Twitter, e que o sistema de inteligência artificial já conhecia.
“Numa das tácticas, em vez de juntar uma longa lista de palavras neutras a frases ofensivas, minimizámos os obstáculos à legibilidade ao adicionar apenas uma palavra. Escolhemos ‘amor’ porque, intuitivamente, é uma palavra que não está correlacionada com discurso de ódio”, explica a equipa no relatório. O objectivo era ver se os sistemas de detecção de comentários tóxicos eram capazes de perceber o truque. Não eram.
Frases como “Odeio-te, amor” escapavam aos filtros. No sistema do Google, frases como “O aquecimento climático vai acontecer. Se tiveres outra opinião, és um idiota” ou "São estúpidos e ignorantes sem classe” passavam de "provavelmente tóxicas" para “incertas” quando os investigadores anexavam a palavra amor.
Os investigadores também repararam que todos os sistemas identificavam “falsos positivos” com muita facilidade quando as frases incluíam palavrões. “Não é evidente quais são os limites para estas palavras. Presumimos, contudo, que há muitos falsos positivos quando a existência de asneiras numa frase não está a ofender uma pessoa ou grupo em particular”, notaram.
Para os investigadores, a forma de melhorar os sistemas não é criar novos sistemas, mas investir mais nas bases de dados com que são treinados. “Adicionar texto ‘benigno’ a frases de ódio [usadas para treinar os sistemas] ajuda o modelo a saber encontrar os elementos que são relevantes para determinar se o texto é odioso. Isto elimina o efeito negativo de adicionar palavras irrelevantes”, concluem os investigadores.